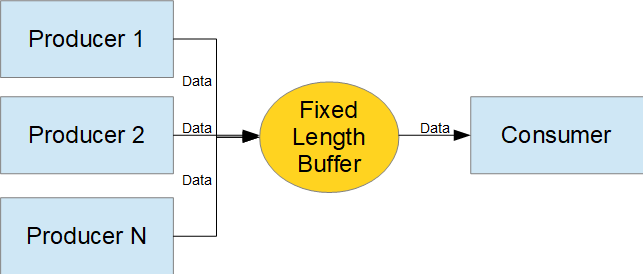
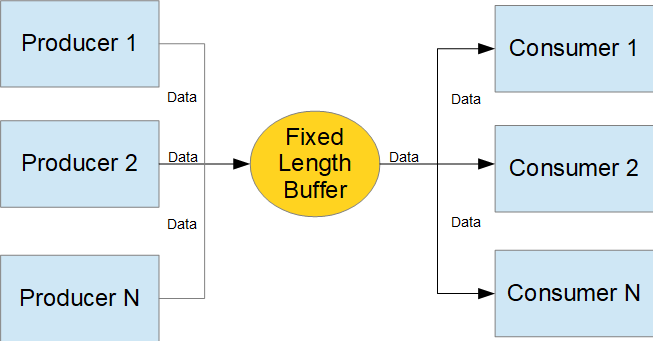
Parallel Comparison of C++ and Ada Producer-Consumer Implementations
Producer Consumer Comparison
The C++ source code for this example is taken from the blog post here by Andrew Wei. A detailed description of the C++ software is given in the blog post.
This solution is shown in parallel with a corresponding Ada solution.
Both C++ and Ada separate interface specifications from implementation. C++ uses the header file, in this case the file named Buffer.hpp, to provide the interface specification for the buffer used in this example. C++ is not very strict about what goes into a header file and what goes into a .cpp file. The Ada version creates an Ada package. The Ada package specification defines the task types named producer_Int and consumer_Int. The buffer shared by all instances of producer_int and consumer_int is defined within the Ada package body file.
Interface Specification Files
| Ada | C++ |
package pc_tasks is task type produce_Int (Id : Natural); task type consume_Int (Id : Natural); end pc_tasks; |
//
// Buffer.hpp
// ProducerConsumer
//
// Created by Andrew Wei on 5/31/21.
//
#ifndef Buffer_hpp
#define Buffer_hpp
#include <mutex>
#include <condition_variable>
#include <stdio.h>
#define BUFFER_CAPACITY 10
class Buffer {
// Buffer fields
int buffer [BUFFER_CAPACITY];
int buffer_size;
int left; // index where variables are put inside of buffer (produced)
int right; // index where variables are removed from buffer (consumed)
// Fields for concurrency
std::mutex mtx;
std::condition_variable not_empty;
std::condition_variable not_full;
public:
// Place integer inside of buffer
void produce(int thread_id, int num);
// Remove integer from buffer
int consume(int thread_id);
Buffer();
};
#endif /* Buffer_hpp */ |
This comparison shows the interface for Ada task types while the C++ interface (.hpp) file shows the interface for the Buffer class. The C++ interface definition defines the interfaces, both public and private, to the Buffer class.
Shared Buffer Implementations
The Ada package body contains both the definition and implementation of the shared buffer object and the implementation of the task types.
| Ada | C++ |
with Ada.Text_IO; use Ada.Text_IO;
with Ada.Numerics.Discrete_Random;
package body pc_tasks is
type Index_T is mod 10; -- Modular type for 10 values
type Circular_Array is array (Index_T) of Integer;
protected buffer is
entry produce (Item : in Integer);
entry consume (Item : out Integer);
private
Buf : Circular_Array;
P_Index : Index_T := Index_T'First;
C_Index : Index_T := Index_T'First;
Buf_Size : Natural := 0;
end buffer;
protected body buffer is
entry produce (Item : in Integer) when Buf_Size < Index_T'Modulus is
begin
Buf (P_Index) := Item;
P_Index := P_Index + 1;
Buf_Size := Buf_Size + 1;
end produce;
entry consume (Item : out Integer) when Buf_Size > 0 is
begin
Item := Buf (C_Index);
C_Index := C_Index + 1;
Buf_Size := Buf_Size - 1;
end consume;
end buffer;
task body produce_Int is
subtype decimal is Integer range 1 .. 10;
package rand_int is new Ada.Numerics.Discrete_Random (decimal);
use rand_int;
value : decimal;
seed : Generator;
begin
Reset (seed);
for I in 1 .. 4 loop
value := Random (seed);
buffer.produce (value);
Put_Line ("Task" & Id'Image & " produced" & value'Image);
delay 0.1;
end loop;
end produce_Int;
task body consume_Int is
Num : Integer;
begin
for I in 1 .. 6 loop
buffer.consume (Num);
Put_Line ("Task" & Id'Image & " consumed" & Num'Image);
delay 0.1;
end loop;
end consume_Int;
end pc_tasks; |
//
// Buffer.cpp
// ProducerConsumer
//
// Created by Andrew Wei on 5/31/21.
//
#include <iostream>
#include "Buffer.hpp"
Buffer::Buffer() {
buffer_size = 0;
left = 0;
right = 0;
}
void Buffer::produce(int thread_id, int num) {
// Acquire a unique lock on the mutex
std::unique_lock<std::mutex> unique_lock(mtx);
std::cout << "thread " << thread_id << " produced " << num << "\n";
// Wait if the buffer is full
not_full.wait(unique_lock, [this]() {
return buffer_size != BUFFER_CAPACITY;
});
// Add input to buffer
buffer[right] = num;
// Update appropriate fields
right = (right + 1) % BUFFER_CAPACITY;
buffer_size++;
// Unlock unique lock
unique_lock.unlock();
// Notify a single thread that buffer isn't empty
not_empty.notify_one();
}
int Buffer::consume(int thread_id) {
// Acquire a unique lock on the mutex
std::unique_lock<std::mutex> unique_lock(mtx);
// Wait if buffer is empty
not_empty.wait(unique_lock, [this]() {
return buffer_size != 0;
});
// Getvalue from position to remove in buffer
int result = buffer[left];
std::cout << "thread " << thread_id << " consumed " << result << "\n";
// Update appropriate fields
left = (left + 1) % BUFFER_CAPACITY;
buffer_size--;
// Unlock unique lock
unique_lock.unlock();
// Notify a single thread that the buffer isn't full
not_full.notify_one();
// Return result
return result;
} |
The Ada part of the package implementing the shared buffer is isolated below, along with a repeat of the C++ Buffer class implementation.
| Ada | C++ |
type Index_T is mod 10; -- Modular type for 10 values
type Circular_Array is array (Index_T) of Integer;
protected buffer is
entry produce (Item : in Integer);
entry consume (Item : out Integer);
private
Buf : Circular_Array;
P_Index : Index_T := Index_T'First;
C_Index : Index_T := Index_T'First;
Buf_Size : Natural := 0;
end buffer;
protected body buffer is
entry produce (Item : in Integer) when Buf_Size < Index_T'Modulus is
begin
Buf (P_Index) := Item;
P_Index := P_Index + 1;
Buf_Size := Buf_Size + 1;
end produce;
entry consume (Item : out Integer) when Buf_Size > 0 is
begin
Item := Buf (C_Index);
C_Index := C_Index + 1;
Buf_Size := Buf_Size - 1;
end consume;
end buffer; |
//
// Buffer.cpp
// ProducerConsumer
//
// Created by Andrew Wei on 5/31/21.
//
#include <iostream>
#include "Buffer.hpp"
Buffer::Buffer() {
buffer_size = 0;
left = 0;
right = 0;
}
void Buffer::produce(int thread_id, int num) {
// Acquire a unique lock on the mutex
std::unique_lock<std::mutex> unique_lock(mtx);
std::cout << "thread " << thread_id << " produced " << num << "\n";
// Wait if the buffer is full
not_full.wait(unique_lock, [this]() {
return buffer_size != BUFFER_CAPACITY;
});
// Add input to buffer
buffer[right] = num;
// Update appropriate fields
right = (right + 1) % BUFFER_CAPACITY;
buffer_size++;
// Unlock unique lock
unique_lock.unlock();
// Notify a single thread that buffer isn't empty
not_empty.notify_one();
}
int Buffer::consume(int thread_id) {
// Acquire a unique lock on the mutex
std::unique_lock<std::mutex> unique_lock(mtx);
// Wait if buffer is empty
not_empty.wait(unique_lock, [this]() {
return buffer_size != 0;
});
// Getvalue from position to remove in buffer
int result = buffer[left];
std::cout << "thread " << thread_id << " consumed " << result << "\n";
// Update appropriate fields
left = (left + 1) % BUFFER_CAPACITY;
buffer_size--;
// Unlock unique lock
unique_lock.unlock();
// Notify a single thread that the buffer isn't full
not_full.notify_one();
// Return result
return result;
} |
The Ada buffer definition begins by defining the array type to be used in the shared buffer. Ada allows arrays to be indexed by any discrete type. In this example an Ada modular type is declared and named Index_T. Type Index_T is declared to be "mod 10", which specifies that all its values are in the range of 0 through 9 and all the arithmetic operators return a value within this range. The only arithmetic operator used in this example is "+". Addition on a modular type is modular. Thus, in this example, 9 + 1 yields 0, which is exactly as needed for a circular buffer.
Type Circular_Array is an array indexed by Index_T. Every element of Circular_Array is an Integer.
Ada protected objects are protected against race conditions. They are specifically used for data shared by Ada tasks. Ada tasks are commonly implemented as operating system threads, but may also be used on a bare-bones system using only a compiler-generated Ada runtime.
The protected object is named buffer. It is separated into a specification and an implementation, but both parts in this example are contained in the package body. The protected specification declares the name of the protected object. There are three kinds of methods that may be used inside a protected object: procedures, entries and functions. Procedures have exclusive unconditional read-write access to the data in the protected object. Entries have conditional read-write access to the data in a shared object. Functions have shared read-only access to the data in the protected object. This example only uses two entries. The private portion of the protected object contains the definition of the data members in the protected object. Buf is an instance of Circular_Array. P_Index is an instance of the Index_T type and is used by the producer to add new data to the protected object. C_Index is an instance of Index_T type and is used by the consumer to index data read from the protected object. Buf_Size is an instance of the Natural subtype of Integer. Natural is a pre-defined subtype of Integer with a minimum value of 0. Buf_Size is initialized with the value 0.
The protected body implements the two entries. Each entry has an associated condition which must evaluate to True for the entry to execute. All tasks calling an entry while its controlling condition evaluates to False are implicitly placed in an entry queue for the called entry using a queuing policy of First-In-First-Out (FIFO). The next entry call in the queue is serviced as soon as the condition evaluates to TRUE. Tasks suspended in the entry queue are given access to the protected entry before any new tasks, thus maintaining the temporal condition of the calls.
The produce entry can only write to the protected object when Buf_Size is less than Index_T'Modulus, which in this case evaluates to 10. The consumer entry can only read from the protected object when Buf_Size is greater than 0.
Each entry implicitly handles all locking and unlocking of the protected object. The protected object is locked just before the "begin" reserved word in each entry and is unlocked just before the "end" reserved word in each entry. The modular nature of the index manipulations as well as the implicit lock manipulations explain the relatively simple Ada code compared with the more verbose corresponding C++ code.
Thread Implementations
The Ada task implementations are also contained in the package body while the C++ thread implementations are contained in the main.cpp file. Those corresponding source code sections are compared below.
| Ada | C++ |
task body produce_Int is
subtype decimal is Integer range 1 .. 10;
package rand_int is new Ada.Numerics.Discrete_Random (decimal);
use rand_int;
value : decimal;
seed : Generator;
begin
Reset (seed);
for I in 1 .. 4 loop
value := Random (seed);
buffer.produce (value);
Put_Line ("Task" & Id'Image & " produced" & value'Image);
delay 0.1;
end loop;
end produce_Int;
task body consume_Int is
Num : Integer;
begin
for I in 1 .. 6 loop
buffer.consume (Num);
Put_Line ("Task" & Id'Image & " consumed" & Num'Image);
delay 0.1;
end loop;
end consume_Int; |
// Takes in reference to a buffer and adds a random integer
void produceInt(Buffer &buffer) {
for (int i = 0; i < 4; i++) {
// Generate random number between 1 and 10
int new_int = rand() % 10 + 1;
buffer.produce(i, new_int);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
// Takes in reference to a buffer and returns the latest int added
// in the buffer
void consumeInt(Buffer &buffer) {
for (int i = 0; i < 6; i++) {
buffer.consume(i);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
} |
The Ada tasks have visibility to the buffer protected object because the task bodies and the protected object are both defined within the same package body scope.
The produce_Int task defines an Integer subtype named decimal with valid values in the range of 1 through 10. That type is passed to the generic package Ada.Numerics.Discrete_Random so that random numbers in the range of 1 through 10 will be generated for this program. The random number seed is reset based upon the system clock using the Reset(seed) command. The for loop iterates through the values 1 through 4. Each iteration generates a new random value, writes the value to buffer.produce, outputs the value to standard output and then delays 0.1 seconds (100 milliseconds).
The consumer_int task defines a local integer variable named Num. The for loop iterates through the numbers 1 through 6. Each iteration calls buffer.consume, assigning the entry out parameter to Num, outputs the consumed value and delays 0.1 seconds.
Program Entry Points
While the program entry point for a C++ program is named "main", the program entry point for an Ada program may have any name chosen by the programmer. Note that the Ada entry point is a procedure, meaning it does not return any value and that procedure has no parameters.
| Ada | C++ |
with pc_tasks; use pc_tasks;
with Ada.Text_IO; use Ada.Text_IO;
procedure Main is
begin
Put_Line("Executing code in main...");
declare
Produce_Task0 : produce_Int (0);
Consume_Task0 : consume_Int (1);
Produce_Task1 : produce_Int (2);
Consume_Task1 : consume_Int (3);
Produce_Task2 : produce_Int (4);
begin
null;
end;
Put_Line ("Done!");
end Main; |
int main(int argc, const char * argv[]) {
std::cout << "Executing code in main...\n";
// Initialize random seed
srand (time(NULL));
// Create Buffer
Buffer buffer;
// Create a thread to produce
std::thread produceThread0(produceInt, std::ref(buffer));
std::thread consumeThread0(consumeInt, std::ref(buffer));
std::thread produceThread1(produceInt, std::ref(buffer));
std::thread consumeThread1(consumeInt, std::ref(buffer));
std::thread produceThread2(produceInt, std::ref(buffer));
produceThread0.join();
produceThread1.join();
produceThread2.join();
consumeThread0.join();
consumeThread1.join();
std::cout << "Done!\n";
return 0;
} |
Ada does not provide a "join()" method. Instead, the code block in which a task or set of task is declared cannot complete until all the tasks within that code block complete. The idiom shown above declared the 5 task type instances within an inner code block, which does not complete until all five of the tasks have terminated. Upon completion of that inner block the message "Done!" is output to standard output.
Complete code listings for both languages
| Ada | C++ |
package pc_tasks is task type produce_Int (Id : Natural); task type consume_Int (Id : Natural); end pc_tasks; |
//
// Buffer.hpp
// ProducerConsumer
//
// Created by Andrew Wei on 5/31/21.
//
#ifndef Buffer_hpp
#define Buffer_hpp
#include <mutex>
#include <condition_variable>
#include <stdio.h>
#define BUFFER_CAPACITY 10
class Buffer {
// Buffer fields
int buffer [BUFFER_CAPACITY];
int buffer_size;
int left; // index where variables are put inside of buffer (produced)
int right; // index where variables are removed from buffer (consumed)
// Fields for concurrency
std::mutex mtx;
std::condition_variable not_empty;
std::condition_variable not_full;
public:
// Place integer inside of buffer
void produce(int thread_id, int num);
// Remove integer from buffer
int consume(int thread_id);
Buffer();
};
#endif /* Buffer_hpp */ |
with Ada.Text_IO; use Ada.Text_IO;
with Ada.Numerics.Discrete_Random;
package body pc_tasks is
type Index_T is mod 10; -- Modular type for 10 values
type Circular_Array is array (Index_T) of Integer;
protected buffer is
entry produce (Item : in Integer);
entry consume (Item : out Integer);
private
Buf : Circular_Array;
P_Index : Index_T := Index_T'First;
C_Index : Index_T := Index_T'First;
Buf_Size : Natural := 0;
end buffer;
protected body buffer is
entry produce (Item : in Integer) when Buf_Size < Index_T'Modulus is
begin
Buf (P_Index) := Item;
P_Index := P_Index + 1;
Buf_Size := Buf_Size + 1;
end produce;
entry consume (Item : out Integer) when Buf_Size > 0 is
begin
Item := Buf (C_Index);
C_Index := C_Index + 1;
Buf_Size := Buf_Size - 1;
end consume;
end buffer;
task body produce_Int is
subtype decimal is Integer range 1 .. 10;
package rand_int is new Ada.Numerics.Discrete_Random (decimal);
use rand_int;
value : decimal;
seed : Generator;
begin
Reset (seed);
for I in 1 .. 4 loop
value := Random (seed);
buffer.produce (value);
Put_Line ("Task" & Id'Image & " produced" & value'Image);
delay 0.1;
end loop;
end produce_Int;
task body consume_Int is
Num : Integer;
begin
for I in 1 .. 6 loop
buffer.consume (Num);
Put_Line ("Task" & Id'Image & " consumed" & Num'Image);
delay 0.1;
end loop;
end consume_Int;
end pc_tasks; |
//
// Buffer.cpp
// ProducerConsumer
//
// Created by Andrew Wei on 5/31/21.
//
#include <iostream>
#include "Buffer.hpp"
Buffer::Buffer() {
buffer_size = 0;
left = 0;
right = 0;
}
void Buffer::produce(int thread_id, int num) {
// Acquire a unique lock on the mutex
std::unique_lock<std::mutex> unique_lock(mtx);
std::cout << "thread " << thread_id << " produced " << num << "\n";
// Wait if the buffer is full
not_full.wait(unique_lock, [this]() {
return buffer_size != BUFFER_CAPACITY;
});
// Add input to buffer
buffer[right] = num;
// Update appropriate fields
right = (right + 1) % BUFFER_CAPACITY;
buffer_size++;
// Unlock unique lock
unique_lock.unlock();
// Notify a single thread that buffer isn't empty
not_empty.notify_one();
}
int Buffer::consume(int thread_id) {
// Acquire a unique lock on the mutex
std::unique_lock<std::mutex> unique_lock(mtx);
// Wait if buffer is empty
not_empty.wait(unique_lock, [this]() {
return buffer_size != 0;
});
// Getvalue from position to remove in buffer
int result = buffer[left];
std::cout << "thread " << thread_id << " consumed " << result << "\n";
// Update appropriate fields
left = (left + 1) % BUFFER_CAPACITY;
buffer_size--;
// Unlock unique lock
unique_lock.unlock();
// Notify a single thread that the buffer isn't full
not_full.notify_one();
// Return result
return result;
} |
with pc_tasks; use pc_tasks;
with Ada.Text_IO; use Ada.Text_IO;
procedure Main is
begin
Put_Line("Executing code in main...");
declare
Produce_Task0 : produce_Int (0);
Consume_Task0 : consume_Int (1);
Produce_Task1 : produce_Int (2);
Consume_Task1 : consume_Int (3);
Produce_Task2 : produce_Int (4);
begin
null;
end;
Put_Line ("Done!");
end Main; |
//
// main.cpp
// ProducerConsumer
//
// Created by Andrew Wei on 5/30/21.
//
#include <thread>
#include <iostream>
#include "Buffer.hpp"
#include <stdlib.h>
// Takes in reference to a buffer and adds a random integer
void produceInt(Buffer &buffer) {
for (int i = 0; i < 4; i++) {
// Generate random number between 1 and 10
int new_int = rand() % 10 + 1;
buffer.produce(i, new_int);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
// Takes in reference to a buffer and returns the latest int added
// in the buffer
void consumeInt(Buffer &buffer) {
for (int i = 0; i < 6; i++) {
buffer.consume(i);
std::this_thread::sleep_for(std::chrono::milliseconds(100));
}
}
int main(int argc, const char * argv[]) {
std::cout << "Executing code in main...\n";
// Initialize random seed
srand (time(NULL));
// Create Buffer
Buffer buffer;
// Create a thread to produce
std::thread produceThread0(produceInt, std::ref(buffer));
std::thread consumeThread0(consumeInt, std::ref(buffer));
std::thread produceThread1(produceInt, std::ref(buffer));
std::thread consumeThread1(consumeInt, std::ref(buffer));
std::thread produceThread2(produceInt, std::ref(buffer));
produceThread0.join();
produceThread1.join();
produceThread2.join();
consumeThread0.join();
consumeThread1.join();
std::cout << "Done!\n";
return 0;
} |
Summary
The same producer-consumer problem can be solved using both Ada and C++. The C++ approach to the producer-consumer pattern requires far more attention to low level details than does the Ada approach to the producer-consumer pattern. The greatest difference in the two approaches is the requirement for the C++ programmer to explicitly manipulate mutex locking/unlocking and suspended thread wait and notification commanding.